Artificial intelligence is rapidly being adopted across financial services, compliance, governance and risk management as firms seek to increase efficiency without expanding headcount. Yet while general-purpose AI tools have become widely accessible, their usefulness inside regulated enterprises remains limited. The challenge is how can institutional knowledge be made available to AI in a controlled and auditable way?
Longshore Labs has focused on this question over the past two years. The Cayman-based financial technology firm has spent the last 18 months integrating leading AI engines into enterprise software designed specifically for governance teams operating under regulatory constraints.
Rather than experimenting with AI as a productivity shortcut, Longshore has approached the technology as an infrastructure problem that requires deliberate design to ensure reliability and control.
Why general AI falls short inside enterprises
Most AI systems used today in fintech are powered by large language models (LLMs). These models are trained on vast quantities of publicly available text and are highly effective at summarising information, answering questions and generating structured explanations. However, they do not have access to an organisation’s internal knowledge.
When an LLM is asked a question about a firm’s policies, regulatory interpretations or historical decisions, it does not retrieve an answer from internal records. Instead, it infers a response based on patterns learned from public data. Such inference without grounding can produce responses that are incomplete, inconsistent or simply wrong.
Longshore Labs treats this not as a limitation of AI itself. The models are capable, but they need structured, governed access to enterprise knowledge.
Most financial institutions already possess exactly the information an AI system would need to be effective. This includes internal policies and procedures, regulatory guidance and interpretations, risk frameworks and methodologies, research papers, technical memoranda, and historical case notes documenting prior decisions.
The problem is that this information is proprietary, fragmented across systems and not prepared in a way that AI can safely use. Public AI tools cannot access it, and exposing sensitive documents to AI models creates unacceptable governance and data-risk concerns.
Training AI on internal documents is not the answer
A common assumption is that enterprises should simply train or fine-tune AI models on their internal data. In practice, this approach introduces significant challenges. Training is expensive and slow, models quickly become outdated as policies change, and auditability is reduced once knowledge is absorbed into model weights. Most critically, governance teams lose fine-grained control over what information the AI is using and when.
What regulated organisations actually need is not a model that “knows everything”, but a system that allows AI to access approved knowledge only when required, for the sole purpose of answering a specific question, while leaving accountability and decision-making with humans.
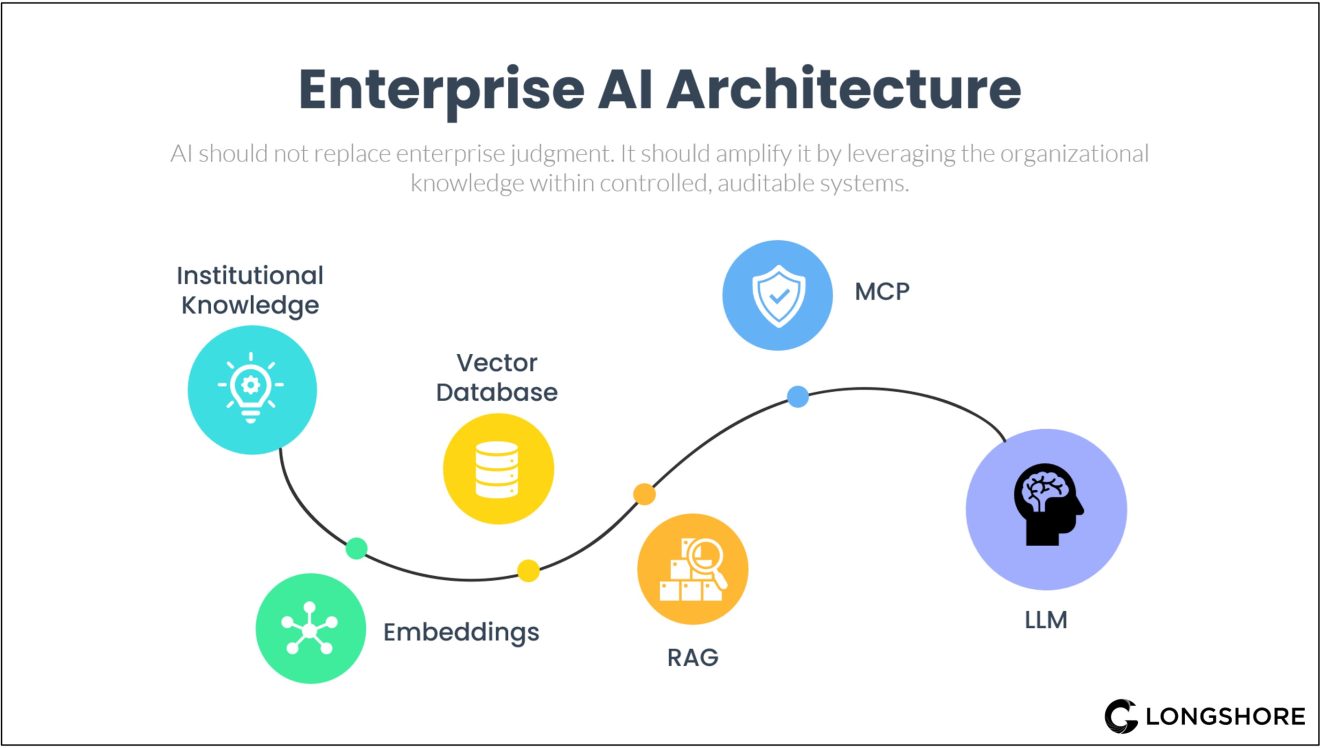
The solution Longshore has implemented avoids retraining models altogether. Instead, enterprise documents are transformed into representations that capture meaning rather than keywords. Those representations are stored in specialised databases and selectively retrieved when a question is asked. The relevant context is then provided to the AI at the moment it generates a response.
This approach is built on three core components: embeddings, vector databases and retrieval-augmented generation (RAG).
A simple analogy: the smart librarian
An LLM can be thought of as a highly articulate consultant, capable of reasoning, explaining complex topics and communicating clearly. But also one who has never read the organisation’s internal documents.
Now imagine pairing that consultant with a smart librarian. When a question is asked, the librarian finds the most relevant internal materials and hands them to the consultant, who then responds using only the given information.
In this analogy, the document summaries are embeddings, the librarian is the vector database, and the overall interaction is retrieval-augmented generation.
Embeddings – turning documents into meaning
Embeddings convert text into mathematical representations of meaning. They allow systems to recognise that different phrases may refer to the same underlying concept. For example, “high-risk jurisdiction”, “FATF grey-listed country”, and “sanctions-exposed geography” may use different words but describe a similar risk category.
By working at the level of meaning rather than exact wording, embeddings allow AI systems to understand what documents are about, not just what they say.
Vector databases – storing and retrieving meaning
A vector database stores these meaning-based representations and enables rapid retrieval of relevant information, even when the wording of a question does not match the original source material. Unlike traditional databases, which depend on exact matches, vector databases search semantically.
Within Longshore’s platforms, this ensures that the most relevant policies, guidance or research are consistently retrieved in response to a query, providing stable and predictable results across teams.
Retrieval-augmented generation – grounding AI responses
Retrieval-augmented generation is the mechanism that brings everything together. When a user asks a question, the system interprets the intent, retrieves the most relevant approved internal documents, and supplies only that selected context to the AI model. The model then generates its response based on enterprise-approved information rather than general assumptions.
This ensures accuracy and consistency, while preserving a clear link between each response and its source material.
MCP: governance at the architecture level
Sitting above this retrieval layer is the Model Context Protocol (MCP), which acts as the governance and control mechanism. The MCP defines how, when and under what rules context is provided to AI models. It ensures that only authorised data sources are accessed, that sensitive information is protected, and that the AI receives no more information than is strictly necessary for the task at hand.
The Model Context Protocol functions both a secure courier and a rulebook, making AI access controlled and fully auditable, which is essential for strong governance and regulatory alignment.
Reducing risk through design
This architecture fundamentally changes the risk profile of enterprise AI. Rather than relying on guesswork, AI operates within clearly defined knowledge boundaries. Information is versioned and controlled, responses can be traced directly back to source documents, and updates can be applied instantly without retraining models.
Crucially, human accountability remains intact. AI acts as decision support, not an autonomous authority, aligning naturally with regulatory expectations around explainability and oversight.
Without this structure, organisations often fall back on ad hoc use of public AI tools. Employees manually paste documents into chat interfaces, outcomes depend on individual prompting skill and responses vary widely. Institutional knowledge remains fragmented, audit trails are weak and governance depends on personal discipline rather than system design, which raises both operational and regulatory risk.
AI should not replace enterprise judgment. It should amplify it by leveraging organisational knowledge within controlled, auditable systems.
With this architecture in place, staff gain consistent access to reliable answers grounded in approved internal information. Time spent searching for documents or reconciling conflicting guidance is reduced, decision support improves, and governance remains embedded throughout the process. AI becomes a dependable assistant rather than an unpredictable tool.
Making knowledge available the right way
Enterprise AI becomes truly valuable not when models become more powerful, but when knowledge is made accessible in a controlled, explainable and repeatable way. By transforming documents into embeddings, organising them in vector databases, governing access through MCP, and delivering context via RAG, organisations move beyond experimentation toward engineered intelligence.
This is how AI stops guessing and starts supporting real decisions at scale. And it is the architectural philosophy that underpins Longshore Labs’ approach to enterprise AI in regulated environments, developed in close collaboration with industry stakeholders.

Lenin Kumar Perumalsamy, the founder of Longshore Labs, is a visionary in software development with over 22 years of experience in Alternative Investments.



